class: center, middle # Top-Down Parsing _CMPU 331 - Compilers_ --- # Stages of Compilation 1. Lexical Analysis 2. Parsing (also called Syntax Analysis) 3. Semantic Analysis 4. Optimization 5. Code Generation 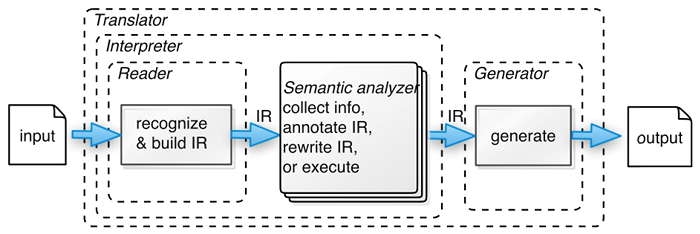 (source: _Language Implementation Patterns_ by Terence Parr) --- # Context-Free Grammar Grammar: ``` E → E * E | E + E | (E) | id ``` String: ``` (id + id) * (id + id) ``` --- # Derivation Grammar: ``` E → E * E | E + E | (E) | id ```  --- # Derivation Grammar: ``` E → E * E | E + E | (E) | id ``` String: ``` id + id * id ``` --- # Derivation Grammar: ``` E → E * E | E + E | (E) | id ```  --- # Derivation There are two different ways we could build the parse tree.  --- # Left-Most Derivation Left-most derivation replaces the left-most non-terminal at each step. ``` 1. E 2. E * E 3. E + E * E 4. id + E * E 5. id + id * E 6. id + id * id ```  --- # Right-Most Derivation Right-most derivation replaces the right-most non-terminal at each step. ``` 1. E 2. E * E 3. E * id 4. E + E * id 5. E + id * id 6. id + id * id ```  --- # Parsing Concepts * Context-free grammars * Derivations, left-most or right-most * Left-to-right scan of input * Lookahead --- # Different Kinds of Parsers LL(k) grammars * First "L" means "left-to-right" scan of input * Second "L" means "left-most derivation" * The "k" says how many tokens it looks ahead LL(1) parsers lookahead by one token --- # Different Kinds of Parsers LR(k) grammars * "L" means "left-to-right" scan of input * "R" means "right-most derivation" * The "k" says how many tokens it looks ahead LR(1) parsers lookahead by one token --- # Different Kinds of Parsers LALR parser * "LA" means "look-ahead" * "L" means "left-to-right" scan of input * "R" means "right-most derivation" LALR parsers are simplified LR parsers, somewhat weaker than LR(1) parsers --- # LL(1) or Predictive Parsers * Each step has only one choice of production * When a non-terminal **A** is left-most in the derivation * There is a unique production **A → α** to use * Or, an error state if there is no production to use * What production to select for a given non-terminal and input token can be represented in a parse table --- # Parsing Table Grammar: ``` <expr> ::= <id> <rep> <rep> ::= <empty> | + <expr> <id> ::= x | y ``` LL(1) parsing table: | x | y | + | EOF ------ | --- | --- | --- | --- expr | id rep | id rep | - | - rep | - | - | + expr | empty id | x | y | - | - When the current non-terminal is **expr** and next token is "x", use the production **expr → id rep**. --- # Using Parsing Tables * For the left-most non-terminal **S** * Look at the next input token **a** * Choose the production shown at **[S,a]** * Stack records * Non-terminals to be expanded * Terminals to be matched against input * Top of stack = left-most pending terminal or non-terminal * Reject on reaching error state * Accept on end of input & empty stack --- # Notes on LL(1) Parsing Tables * Most programming language CFGs are not LL(1) * LL(1) can't handle any entry with multiple definitions * Ambiguous grammars * Left-recursive grammars * Grammars that aren't left-factored * Other cases --- # Ambiguity * A grammar is _ambiguous_ if it has more the one parse tree for some input  --- # Ambiguity * A grammar is _ambiguous_ if it has more the one parse tree for some input  --- # Left Recursion * A left-recursive grammar has a non-terminal as the first element of its own production ``` S → S α (for some α) ``` --- # Left Factoring * Left-factoring modifies a grammar, to factor out common prefixes of productions * For example, **T** is the correct production for either alternative: ``` E → T + E | T ``` * The correct production can't be predicted with a single token lookahead * So, we split the problematic rule into two rules, each with a unique start ``` E → T X X → + E | [empty] ```