
Linkage between original and annotation documents is accomplished using the HyTime-based TEI addressing mechanisms for element linkage.
The separate markup strategy is in essence a finely linked hypertext format where the links signify a semantic role rather than navigational options. That is, the links signify the locations where markup contained in a given annotation document would appear in the document to which it is linked. As such the annotation information comprises remote markup which is virtually added to the document to which it is linked. In principle, the two documents could be merged to form a single document containing all the markup in each. This approach has several advantages for corpus-based research:
The hyper-document comprising each text in the corpus and its annotations will consist of several documents. The base or "hub" document is the unannotated document containing only primary data markup. The hub document is "read only" and is not modified in the annotation process. Each annotation document is a proper SGML document with a DTD, containing annotation information linked to its appropriate location in the hub document or another annotation document.
All annotation documents are linked to the SGML original (containing the primary data) or other annotation documents using one-way links. The exception is output of the aligner for parallel texts, which will consist of an SGML document containing only two-way links associating locations in two documents in different languages. The two linked documents are two documents containing the relevant structural information, such as sentence or word boundaries. The overall architecture is described by the figure below.
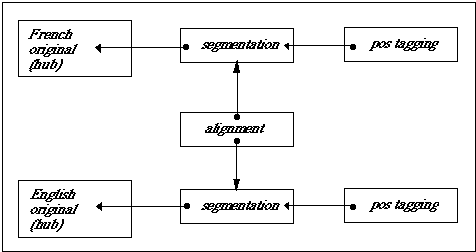
Following this model, the CES provides DTDs for the different types of annotation information, described below.
Both the TEI and HyTime provide means to handle situations where ID references cannot be used. TEI locators have the advantage that they are more compact than HyTime location ladders. Additionally, the TEI notation is easily made compatible with HyTime by the use of the Hytime notloc form, in conjunction with an appropriate notation declaration. Therefore, it is recommended that in general, TEI locators are used. See TEI P3, chapter 14, "Linking, Segmentation, and Alignment" for a complete description and explanation of TEI locators.
Within the CES we have developed a more precise and concise notation for locators, which uses locations in the SGML tree to point to specific elements (e.g., the third child of the second child of the first child of the root). Annotation documents are linked to the hub or to another annotation document via one-way links, specified in two steps:
As an example of the CES addressing method, consider the following text:
<p>
L'usine, qui devrait être implantée à Eloyes (Vosges) représente
un investissement d'environ 3,7 milliards de yens. Elle fabriquera
des pièces détachées pour la filiale de Minolta en RFA.
<p>
The following is the TEI mechanism for pointing to the first two words inside the <p> element :
<tok from="CHILD (2) (1) (1) (1) (2) (1) STRLOC (1)"
to="CHILD (2) (1) (1) (1) (2) (1) STRLOC (2)">
<tok from="CHILD (2) (1) (1) (1) (2) (1) STRLOC (3)"
to="CHILD (2) (1) (1) (1) (2) (1) STRLOC (7)">
The TEI notation is given in two parts:
<tok from="2.1.1.1.2.1\1" to="2.1.1.1.2.1\2">
<tok from="2.1.1.1.2.1\3" to="2.1.1.1.2.1\7">
The locator 2.1.1.1.2.1\1 is exactly equivalent to the TEI notation CHILD (2) (1) (1) (1) (2) (1) STRLOC (1).
In the example above, locators are used on the from and to attributes on the <tok> element to reference strings of characters to be considered as single tokens, thus accomplishing the addition of remote markup (i.e., the addition of the <tok> elements) to the referenced document. In alignment documents, specification of a character offset is often not required for alignment, which is typically between the entire content of SGML elements (sentences, paragraphs, tokens) in the aligned documents. The same notation can be used in such instances, omitting the character offset:
<link fromLoc="2.1.1.1.2.1" toLoc="2.1.1.1.2.1">
The structure of the DTD constituents is based on the overall principle that one or more "chunks" of a text may be included in the annotation document. These chunks may correspond to parts of the document extracted at different times for annotation, or simply to some subset of the text that has been extracted for analysis. For example, it is likely that within any text, only the paragraph content will undergo morphosyntactic analysis, and titles, footnotes, captions, long quotations, etc. will be omitted or analysed separately.
Elements in cesAna documents will, for the most part, use the notation outlined in the section above on Locators to reference locations in the document which is being annotated, since the identification of sentence boundaries, token boundaries, etc. typically involves pointing to the start and end points of sequences of characters which are not the entire content of an SGML element.
The global attributes are defined at the top of the cesAna DTD and represented by an entity, A.ANA. This entity is used to represent the list of global attributes on the attribute declarations for most elements in the document.
The type attribute should normally be specified on the <cesAna> element, in order to specify the type of annotation contained in the document. Suggested values for the type attribute on the <cesAna> element include:
Note that when the document contains more than one type of annotation, a series of values in quotation marks can be given for the attribute, e.g., "type = "SENT TOK".
Note: the cesHeader is optional in the cesAna DTD, for convenience during processing. However, for data conforming to this DTD which is in a final form or which may be interchanged, the cesHeader is required.
When it appears on the <chunk> element, the type attribute can be used to indicate the type of information with which the chunk is associated, e.g., paragraph data, titles, etc. This is useful when specific portions of a text have been extracted for analysis.
Note also that the header for this text is stored in another file and included in this document as an entity.
<!doctype cesAna PUBLIC "-//CES//DTD cesAna//EN"
<cesAna version="1.5" type="SENT TOK LEX DISAMB" doc=MyText1>
<cesHeader version="2.3">
...
</cesHeader>
<chunkList>
<chunk doc="MyText1" from='1.2.1\1'>
<s >
<tok class='tok' from='1.2.1\1'>
<orth>Les</orth>
<disamb>
<ctag>DMP</ctag>
</disamb>
<lex>
<base>le</base>
<msd>Da-fp--d</msd>
<ctag>DFP</ctag>
</lex>
<lex>
<base>le</base>
<msd>Da-mp--d</msd>
<ctag>DMP</ctag>
</lex>
<lex>
<base>le</base>
<msd>Pp3fpj-</msd>
<ctag>PPJ</ctag>
</lex>
<lex>
<base>le</base>
<msd>Pp3mpj-</msd>
<ctag>PPJ</ctag>
</lex>
</tok>
<tok class='tok' from='1.2.1\5'>
<orth>critères</orth>
<disamb>
<ctag>NCMP</ctag>
</disamb>
<lex>
<base>critère</base>
<msd>Ncmp-</msd>
<ctag>NCMP</ctag>
</lex>
</tok>
<tok class='tok' from='1.2.1\14'>
<orth>se</orth>
<disamb>
<ctag>PPJ</ctag>
</disamb>
<lex>
<base>se</base>
<msd>Pp3msj-</msd>
<ctag>PPJ</ctag>
</lex>
<lex>
<base>se</base>
<msd>Pp3fpj-</msd>
<ctag>PPJ</ctag>
</lex>
<lex>
<base>se</base>
<msd>Pp3fsj-</msd>
<ctag>PPJ</ctag>
</lex>
<lex>
<base>se</base>
<msd>Pp3mpj-</msd>
<ctag>PPJ</ctag>
</lex>
</tok>
<tok class='tok' from='1.2.1\17'>
<orth>basent</orth>
<disamb>
<ctag>VM3P</ctag>
</disamb>
<lex>
<base>baser</base>
<msd>Vmip3p--</msd>
<ctag>VM3P</ctag>
</lex>
<lex>
<base>baser</base>
<msd>Vmsp3p--</msd>
<ctag>VM3P</ctag>
</lex>
</tok>
<tok class='tok' from='1.2.1\24'>
<orth>sur</orth>
<disamb>
<ctag>SP</ctag>
</disamb>
<lex>
<base>sur</base>
<msd>Afpms-</msd>
<ctag>AMS</ctag>
</lex>
<lex>
<base>sur</base>
<msd>Sp</msd>
<ctag>SP</ctag>
</lex>
</tok>
...
</s>
</chunk>
</chunkList>
</cesAna>
Alternatively, if a more concise set of information is desired, the following could be provided for the first token in the example above:
<tok class='tok' from='1.2.1\1'>
<orth>Les</orth><base>le</base><ctag>DMP</ctag></tok>
The cesAna DTD
The cesAna DTD in hypertext navigable format
Alignment may be between primary data documents or between annotation documents containing segmentation information for the aligned units (paragraphs, sentences, tokens etc.). Alignment may be between two or more such documents, which should be identified in the cesHeader of the alignment document (see section 5.3.2).
The global attributes are defined at the top of the cesAna DTD and represented by an entity, A.ALIGN. This entity is used to represent the list of global attributes on the attribute declarations for most elements in the document.
Note that the fromDoc and toDoc attributes are provided for the common case where only two files are being aligned. When three or more files are aligned, it is necessary to identify the files using the <translations> element in the header (see below).
For alignment documents, an important part of the header is the <translations> element, which should contain, for each document being aligned, a translation element identifying and locating the document. The <translations> element is required in order to identify the aligned documents when three or more files are being aligned. When only two files are being aligned, the the fromDoc and toDoc attributes on <cesAlign> element can be used to identify the aligned files.
The n attribute on <translation> elements in the cesHeader may be used to indicate the order in which the aligned documents are referenced in the xtargets attribute on <link> element (see section 5.3.4.2). When three or more files are being aligned using xtargets, this method of indicating the order of file reference is required. When only two documents are being aligned, the order can be indicated using the fromDoc and toDoc attributes on <cesAna>, <linkGrp> and/or <link> elements.
Note: the cesHeader is optional in the cesAlign DTD, for convenience during processing. However, for data conforming to this DTD which is in a final form or which may be interchanged, the cesHeader is required.
In most instances, the documents being aligned in a cesAlign document will be indicated in the fromDoc and toDoc attributes on the <cesAlign> element (when only two documents are aligned), or using the <translations> element in the cesHeader. However, it is also possible to use the fromDoc and toDoc attributes on the <linkGrp> and <link> elements to indicate the documents being aligned. This may be necessary if a single alignment document contains alignment information for more than one pair of files. Therefore, the attributes fromDoc and toDoc are provided on the <linkGrp> and <link> (see below) elements for use where desired or needed.
As for the <linkGrp> element (see above), attributes to handle linkage between two documents are provided on <link>:
The fromLoc and toLoc attributes are used when the data pointed to in each of these attributes is the entire contents of a single SGML element. For data which is not the entire contents of an SGML element, or when referencing more than two locations (for example, for many-to-one alignments) with the CES locator notation, use the mechanisms outlined in section 5.3.4.3.
Note that because the doc attribute on the <xptr> element is defined as #CURRENT, once a value has been specified for this attribute on one instance of <xptr>, all subsequent occurrences of that element will use this value as the default unless it is re-specified. Therefore, verbosity can be reduced by placing all the
<xptr> elements that point to the same document sequentially within the alignment document.
Note that when the SGML ID and IDref mechanism is used to point from one element to another in the same SGML document, the SGML parser will validate the references to ensure that every IDREF points to a valid ID. In the CES, all alignment documents are separate from the documents that are being aligned, and therefore this validation of IDrefs by the SGML parser is lost. However, other software may be used to validate cross-document references, if necessary.
The CES provides a simple means to point to SGML elements in other SGML documents by referring to IDs or any other unique identifying attribute on those elements, using the xtargets attribute on the <link> element. Here is a simple example:
DOC1: <s id=p1s1>According to our survey, 1988 sales of
mineral water and soft drinks were much higher than in 1987, reflecting
the growing popularity of these products.</s>
<s id=p1s2>Cola drink manufacturers in particular achieved above-
average growth rates.</s>
<!-- ... -->
DOC2: <s id=p1s1>Quant aux eaux minérales et aux limonades, elles
rencontrent toujours plus d'adeptes.</s>
<s id=p1s2>En effet, notre sondage fait ressortir des ventes
nettement supérieures à celles de 1987, pour les boissons
à base de cola notamment.</s>
ALIGN DOC:
<linkGrp targType="s">
<link xtargets="p1s1 ; p1s1">
<link xtargets="p1s2 ; p1s2">
</linkGrp>
The IDrefs of the elements to be aligned are given in the xtargets attribute on the <link> element. A semicolon separates the IDref(s) from each document being linked. Many-to-one alignments are specified by providing a list of IDs from any single document, separated by spaces:
<link xtargets="s1 ; s1 s2">
<link xtargets="s23 s24 s25 ; s23 s24">
N-to-zero alignments can also be indicated:
<link xtargets="s1 ; ">
Additionally, any number of files can be aligned using the xtargets attribute:
<link xtargets="s1 ; s1 ; s1">
<link xtargets="s1 ; s1 s2 ; s1">
<link xtargets="s1 ; ; s1">
When more than two files are being aligned, the ordering must be specified in the cesHeader in the alignment document, as indicated above in the description of the cesHeader.
Here is a more extended example using xtargets:
DOC1: <cesDoc version="3.24">
<cesHeader version="2.3">
...
</cesHeader>
<text>
<body id="b1">
<div type=sample id="d1">
<p id="d1p1">
<s id="d1p1s1">J'ai donc dû choisir un autre métier
et j'ai appris à piloter des avions.</s>
<s id="d1p1s2">J'ai volé un peu partout dans le monde.</s>
<s id="d1p1s3">Et la géographie, c'est exact, m'a beaucoup servi.</s>
<s id="d1p1s4">Je savais reconnaître, du premier coup d'oeil, la Chine
de l'Arizona.</s>
<s id="d1p1s5">C'est très utile, si l'on est égaré pendant la nuit.</s>
</p>
</div>
</body>
</text>
</cesDoc>
DOC2: <cesDoc version="3.24">
<cesHeader version="2.3">
...
</cesHeader>
<text>
<body id="b1">
<div type=sample id="d1">
<p id="d1p1">
<s id="d1p1s1">So then I chose another profession, and learned to
pilot aeroplanes.</s>
<s id="d1p1s2">I have flown a little over all parts of the world;
and it is true that geography has been very useful to me.</s>
<s id="d1p1s3">At a glance I can distinguish China from Arizona.</s>
<s id="d1p1s4">If one gets lost in the night, such knowledge is
valuable.</s>
</p>
</div>
</body>
</text>
</cesDoc>
ALIGN DOC:
<cesAlign type=sent version=1.6>
<cesHeader version="2.3">
...
<translations>
<translation trans.loc="text-f.sgml" lang=fr wsd="ISO8859-1" n=1>
<translation trans.loc="text-e.sgml" lang=en wsd="ISO8859-1" n=2>
</translations>
</cesHeader>
<linkList>
<!-- sentence alignments -->
<linkGrp domains="d1 d1" targType="s">
<link xtargets="d1p1s1 ; d1p1s1">
<link xtargets="d1p1s2 d1p1s3 ; d1p1s2">
<link xtargets="d1p1s4 ; d1p1s3">
<link xtargets="d1p1s5 ; d1p1s4">
</linkGrp>
</linkList>
</cesAlign>
If the data to be aligned comprise the content of entire SGML elements (such as <s>, <p>, etc.), and when only two files are to be aligned, the fromLoc and toLoc attributes on the <link> element can be used to accomplish the aliignment. For example:
<link fromLoc="2.1.1.1.2.1" toLoc="2.1.1.1.3.2">
When the data does not comprise the entire content of an SGML element, it must be referenced by the method outlined in section 5.1., Locators. This demands the use of <xptr> elements, since each target must specify a starting and ending location for the referenced string in each of the aligned documents. Therefore it is necessary to specify something like the following:
<xptr id=En1 doc=EN104 from="2.1.1.1.2.1\1" to="2.1.1.1.2.1\5">
<xptr id=Fr1 doc=FR413 from="2.1.1.1.2.1\1" to="2.1.1.1.2.1\8">
<link targets="En1 Fr1">For alignments involving three or more documents, this same mechanism is used, since any number of IDs can be specified in the value field of the targets attribute on the <link> element. For example:
<xptr id=En1 doc=EN104 from="2.1.1.1.2.1\1" to="2.1.1.1.2.1\5">
<xptr id=Fr1 doc=FR413 from="2.1.1.1.2.1\1" to="2.1.1.1.2.1\8">
<xptr id=De1 doc=DE234 from="2.1.1.1.2.1\4" to="2.1.1.1.2.1\12">
<link targets="En1 Fr1 De1">One-to-many and many-to-many alignments are accomplished by using <ptr> elements to associate <xptr> elements, which then may be linked as a group using the mechanisms above. For example, this encoding aligns two sentences in one text with one in another:
<xptr id=Es43 from="2.1.1.1.2.1" to="2.1.1.1.3.2">
<xptr id=Es44 from="2.1.1.1.4.1" to="2.1.1.1.4.2">
<ptr id=Es43.44 targets="Es43 Es44" targOrder=Y>
<link id=Fs42 fromLoc="2.1.1.1.6.1" toLoc="2.1.1.1.6.2">
<link targets="Es43.44 Fs42">In an n-to-zero alignment, only one IDref would appear in the targets attribute on the <link> element.
